This post is something I’ve been working on for a while. It’s about deploying an ElasticSearch cluster on Azure using the ARM JSON Template model. You might think why not use Azure Search, the PaaS offering, or the ElasticSearch offering in Azure Marketplace? Well, the reason is that this work comes from a rehosting of an existing solution that required some specific details and it didn’t fit those offerings. Rehosting the solution also involved being able to automate creating search clusters over and over again which is a nice fit for deploying them via using a JSON template.
Implementation objectives
The objectives of this solution’s implementation is that it should be easy to deploy yet another new cluster. The JSON template should also not hide too many details. With this I mean many of the templates on Azure quickstart templates ask too little and just create resources in the background with out asking how. I’ve tried to make all things as a parameter that should be selectable during deployement. I really hesitated in putting Storage Account And Virtual Network in the JSON template as you may want to decide that externaly. However, thinking of IOPS of the worker nodes, it makes sense that they have a Storage Account of their own. My assumption is also that this deployment can live in a virtual network of its own, so that’s why I create the VNet during deployment. If that is not what you prefer, remove the VNet in the resources section, but you have to find a way to get a unique ip address for the internal load balancer then.
The JSON Template
The solution has two groups of machines behind a Load Balancer each in a Availability Set. The first group (to the right) is a set of proxy nodes that are exposed via a public ip address. These nodes are just a reverse proxy infront of the search cluster exposing an api via port 80/443. It also does some authentication stuff that is removed in this sample solution. The proxy nodes can be smaller 1 cpu machines.
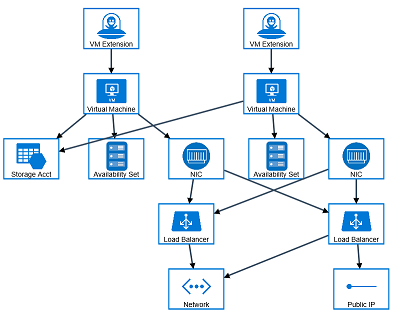
The second group (to the left) is a set of worker nodes where each node has ElasticSearch installed. These nodes are behind an internal Load Balancer in Azure and they are made up of more powerfull machines.
Deployment of the cluster
Deployment of the cluster can be done via powershell, bash script or via the Azure portal. In the references you’ll find a link to my github repo where you have all the sources. The basic idea is that when you need to create a new cluster, you give it a name (-n parameter) and specify how many proxies and workers you need (-x and -w parameters).
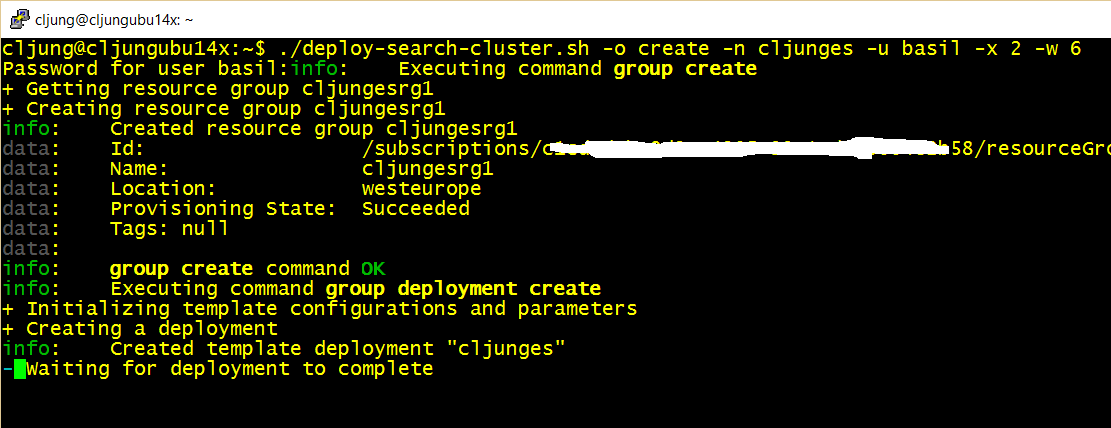
The cluster shares one common storage account that it creates and one common virtual network. The proxies are in one subnet and the workers in another.
Virtual Network
The proxy nodes use dynamic ip addresses which means that they get an ip address from the subnet pool. In my definition, this means that the first proxy get 10.10.1.4, the second 10.10.1.5 and so on, but if the are recycled, rebuilt or otherwise rotated they can get an arbitrary ip address. Since the proxy nodes are stateless, it really doesn’t matter.
The worker nodes use static ip addresses which means they request a specific ip address out of its subnet pool. The first worker gets ip address 10.10.2.101, the second 10.10.2.102 and so on. The internal load balancer has the static ip address of 10.10.2.100.
Installation stuff
Both the proxy and the worker nodes gets their software installed and configured via CustomScriptExtension. There is a special agent running in Windows or Linux VMs for Azure and it can run scripts when the machine is created. These machines each have its own bash script that installs whatever software needed. The deployment routine currently refers to my github repo for pulling the scripts during the processing of the JSON template. This works because I use a public github repo. If you do this in your own environment, you would put all these scripts in an Azure Storage Account and modify the JSON template to point to that.
The proxy machines installs a tiny node.js reverse proxy as well as setting up some test data from Shakespeare quotes. The worker machines does some more heavy lifting since they need to mount a data disk, install java, ElasticSearch and some plugins, create cluster config and start ElasticSearch.
The first proxy node is given a special task and that is to wait for the worker cluster to become available, and when it is, to import Shakespeare quotes as test data. You can see this in the esinstallproxy.sh and shakespeare.sh scripts.
Availability Sets, Fault and Update Domains
A cluster is no good unless the nodes work as a team and cover for one another. The worker nodes are in an Azure Availability Set, and an availability set can configure something called Fault Domains and Update Domains.
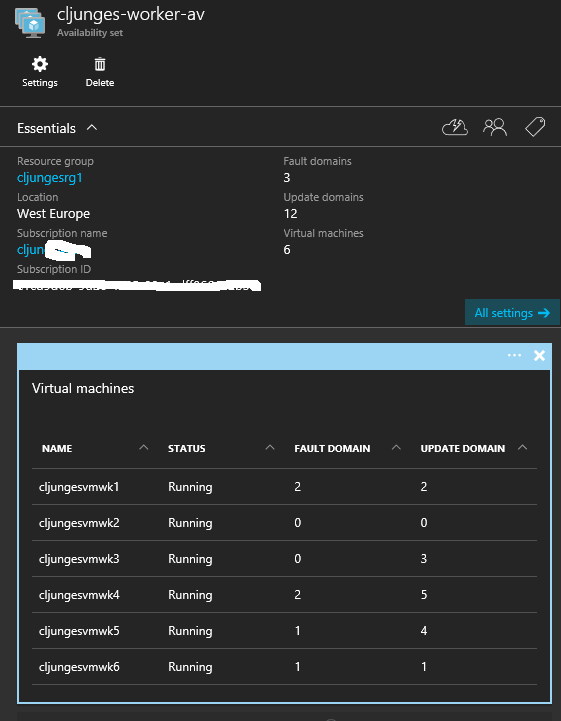
In the above example we have 6 worker nodes and the Availability Set has a configuration of 3 Fault domains and 12 Update domains. Fault domain for Azure is about how many different physical server racks you can deploy your solution in, and having 3 here means that with 6 VMs we have 2 VMs in each rack. If all hell breakes loose and we have a hardware failure we will lose at most 2 servers. Update Domain is how Azure should go about doing maintenance. Since we specified 12 update domains it means that as long as we have 12 or less machines, Azure will only do maintenance on one VM at a time. If we had 13, the 13th machine would be placed in a domain with another and during maintenance then two VMs would be offline for the duration of the maintenance.
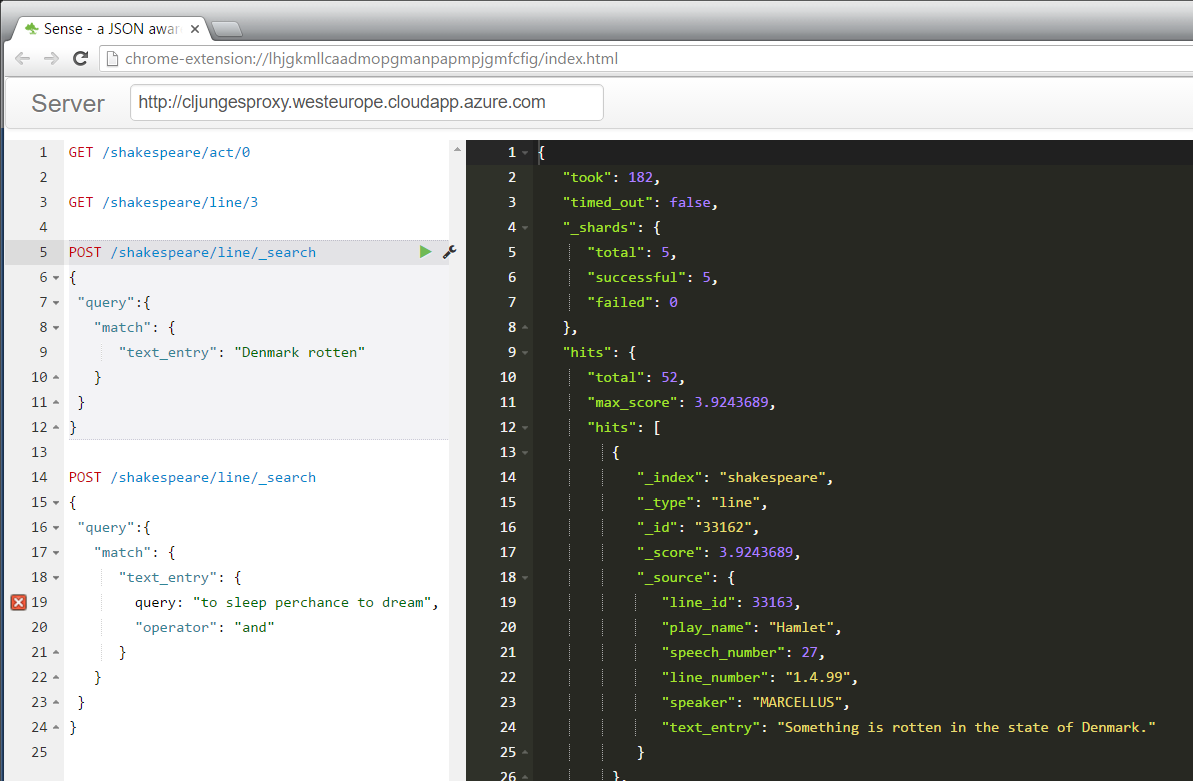
Something is rotten in the state of Denmark
As all Scandinavians know, there is something rotten in the state of Denmark. It is and has always been 🙂 With this solution you can find out where in Shakespeare’s Hamlet it is mentioned.
Summary
There is really nothing here that you can’t find on Azure github quickstart templates. However, most of those are just showing you ideas what could be done and leaving you with alot of work getting it production ready. This example tries to be pretty close to a real production solution even though I had to remove some stuff to keep it generic. The bash and powershell scripts show you how you might possibly integrate this into your own automation scenario.
One final note you might have if you read the bash installation scripts is why I have Salt-stuff there but it’s commented out. It’s actually part of what the real solution does, which is using SaltStack for its configuration management of the cluster.
References
Github repo with all the sources
https://github.com/cljung/az-search-cluster
I’ve also tried to add references in the scripts as to why it does what it does, so please follow thouse references.
Azure Github Quickstart Templates
https://github.com/Azure/azure-quickstart-templates