Ingesting data into storage may be a non exciting task but it is a task that you get back to again and again. There are many tools for uploading files to Azure Storage and there are also many SDKs so you can implement it in most popular languages. I’ve written how you can use the PutBlock APIs in both Java and javascript before and recently I had the chance to implement it i C++ to create a portable solution.
PutBlock and PutBlockList APIs
The Azure Storage APIs PutBlock and PutBlockList are very basic but also very powerful. With PutBlock you upload a chunk of a file which you then repeat until all of the file is uploaded. You commit all of the chunks in one call to PutBlockList which takes all the chunk ids and their respective order. The beauty is that you can upload a large files in parallell by using multiple threads, there by avoiding the sequential processing of first reading a chunk and sending if over the network, then read some more, etc etc. How many threads and how large the chunk size should be may vary from machine to machine, but the goal is to maximize the utilization of the network card.
Azure Storage C++ library
Microsoft do not have full a complete C++ Azure SDK as they have for C#, Java and other languages, but there is a C++ library for Azure Storage called azure-storage-cpp. In a previous post I wrote about how to leverage that and another Microsoft C++ REST library named Casablanca for implementing Azure KeyVault functionality in C++. The sample program I develop in this post builds on the same principles, so instructions for how to build azure-storage-cpp and Casablanca will not be repeated here.
Parallell uploading Sample
Each chunk of the file holds the starting offset in the file, the length of the chunk and its identity.
class FileChunk
{
public:
int id; // seq id of the chunk to read
unsigned long startpos; // offset in file where to start reading
unsigned long length; // length of chunk to read from file
int threadid; // marked by the thread that pulls the piece from the queue
bool completed; // marked by the thread when completed
unsigned long bytesread; // actual bytes read from file
float seconds; // time it took to send this chunk to Azure Storage
utility::string_t block_id; // BlockId for Azure
The list of chunks is stored twice. First in a list so we can keep track of them, and then also in a queue that serves as a way to feed all background threads with work to do.
std::list<FileChunk*> chunkl; std::queue<FileChunk*> queueChunks;
Before creating the threads, we create a list of FileChunk objects and populate the list and queue.
// create chunks and push them on a queue
while (remaining > 0)
{
chunksread++;
long toread = remaining > this->chunkSize ? this->chunkSize : remaining;
FileChunk *fc = new FileChunk(chunksread, (unsigned long)currpos, (unsigned long)toread);
chunkl.push_back(fc);
this->queueChunks.push(fc);
remaining -= toread;
currpos += toread;
}
Then it’s time to create the threads and put them to work.
// create threads that process tasks in the queue
std::list<std::thread*> vt;
for (int n = 1; n <= countThreads; n++)
{
std::thread *t1 = new std::thread( threadproc, n, this );
vt.push_back(t1);
}
The background processing is pretty simple. It just pulls the next chunk to be processed off the queue, reads the file as specified in the FileChunk info, creates a BlockId and sends the chunk to Azure Storage via the PutBlock API, which in the C++ library is called upload_block. Since it is a common queue, we can use as many threads as we want, but there is really no point in having to many since the bottleneck will be throughput on the network cards.
azure::storage::cloud_block_blob blob = this->container.get_block_blob_reference( this->blobName );
std::vector<uint8_t> buffer( this->chunkSize );
// get the next file I/O task from hte queue and read that chunk
while (!this->queueChunks.empty())
{
FileChunk *fc = (FileChunk*)(this->queueChunks.front());
this->queueChunks.pop();
// read the specified chunk from the file
file.seekg(fc->startpos, ios::beg);
file.read((char*)&buffer[0], fc->length);
fc->bytesread = (unsigned long)file.gcount();
// create Azure Block ID value
fc->block_id = utility::conversions::to_base64(fc->id);
auto stream = concurrency::streams::bytestream::open_istream(buffer);
utility::string_t md5 = _XPLATSTR("");
unsigned long t0 = clock();
blob.upload_block(fc->block_id, stream, md5);
fc->seconds = (float)(clock() - t0) / (float)CLOCKS_PER_SEC;
fc->threadid = threadid;
fc->completed = true;
}
When the queue is empty, the threads terminate and the main program continues with the next step which is building a list of the BlockIds and calling the final commit to the PutBlockList API. This method is named upload_block_list in the C++ library.
// wait for all threads to complete
std::list<std::thread*>::iterator itt;
for (itt = vt.begin(); itt != vt.end(); ++itt)
{
(*itt)->join();
}
// create the block list vector from results
this->total_bytes = 0;
std::vector<azure::storage::block_list_item> vbi;
std::list<FileChunk*>::iterator it;
for (it = chunkl.begin(); it != chunkl.end(); ++it)
{
azure::storage::block_list_item *bli = new azure::storage::block_list_item((*it)->block_id);
vbi.push_back(*bli);
this->total_bytes += (*it)->bytesread;
delete (*it);
}
// commit the block list items to Azure Storage
blob1.upload_block_list(vbi);
Running the program
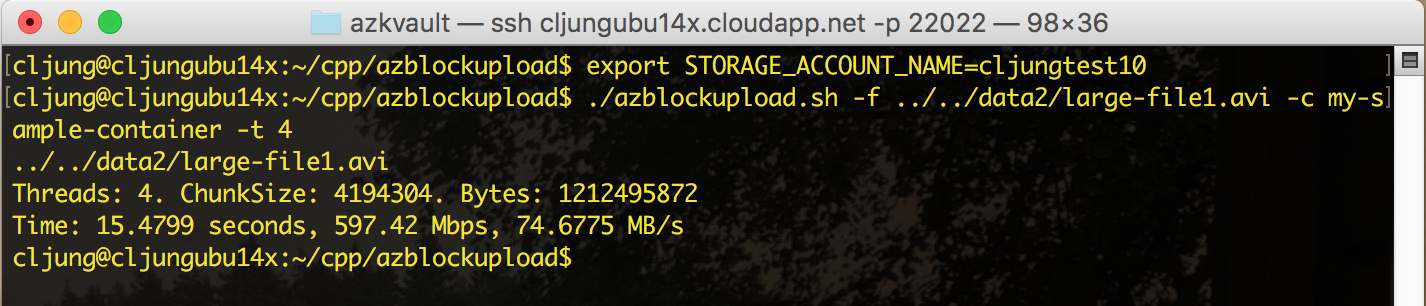
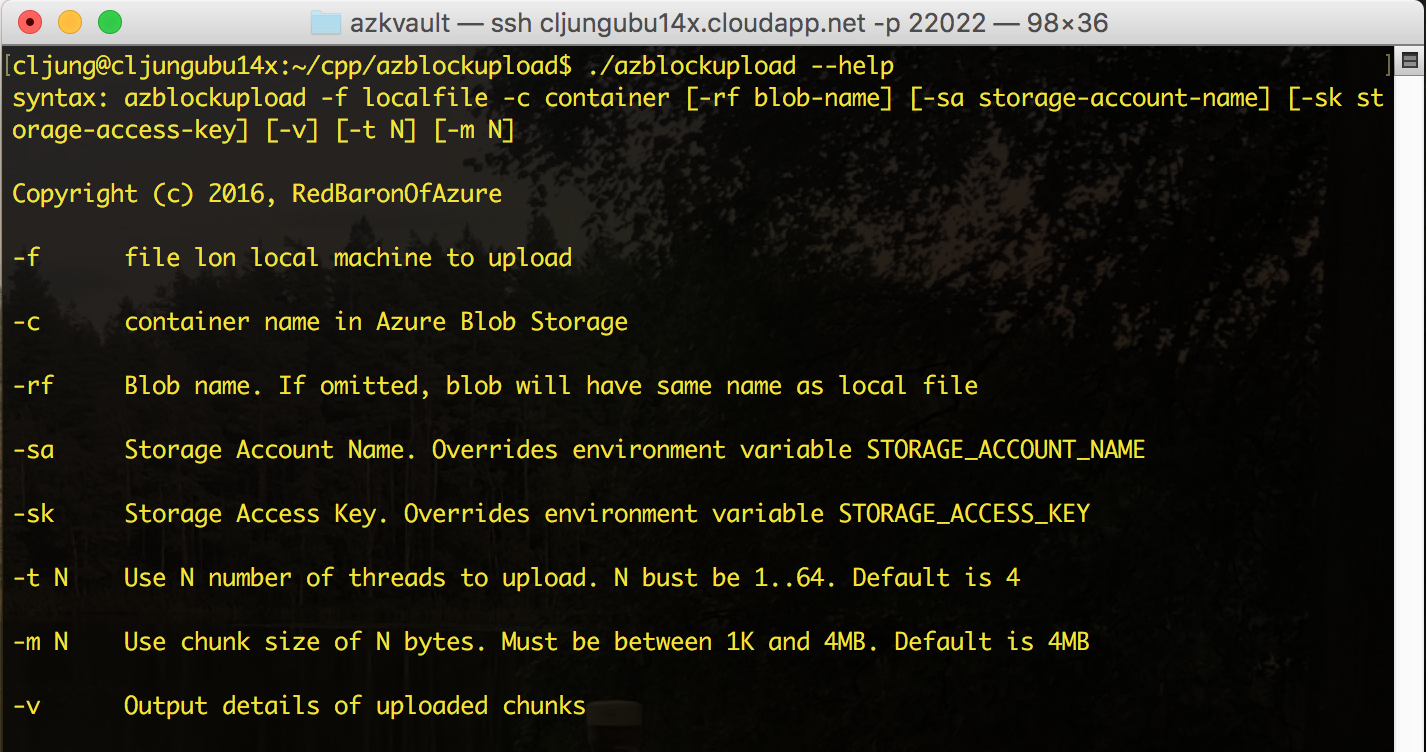
To specify the storage account to be used, you can either pass the account name and key on the command line or you can set it as environment variables called STORAGE_ACCOUNT_NAME and STORAGE_ACCESS_KEY. Then you pass the local filename and the name of the Storage Container on the command line to execute the program. The below is output from running it on a D1 VM with 4 threads uploading a file of 1GB. It’s a pretty impressive performance. To get even better perf, you would need to create a VM in Azure with multiple NICs.
Building the program
The C++ program can be built on Windows, Linux and Mac. The github repo contains a Visual Studio 2015 solution and a makefile that you can use on Linux/Mac. On Windows, installing the azure-storage-cpp is automatic via NuGet (or if you do Install_package wastorage yourself). On Linux/Mac, you have do git clone and build Casablanca and azure-storage-cpp manially.
Summary
The PutBlock/PutBlockList APIs are quite versatile in that you can build data ingestion solutions in almost all popular languages. With the C++ library solution, you can build your own tools that can run on a wide array of machines and devices. C++ might not be the language that you write a lot of code in today, but if you need raw performance and portability, you can interact with Azure Storage quite easily and achieve good performance.
References
Github repo – Source code
https://github.com/cljung/azblockupload
MSDN documentation – PutBlock APIs
https://msdn.microsoft.com/en-us/library/dd135726.aspx
Github – azure-storage-cpp
https://github.com/Azure/azure-storage-cpp
Github – Casablanca C++ REST SDK
https://github.com/microsoft/cpprestsdk
Make sure to look at the wiki page for documentation on how to build it